

Criticising: Download s3 file to local file python
| Gigabyte h110m-s2 ddr4 drivers download | Tomb raider gold pc download iso zone |
| Roundscape 4.6 download torrent | How to download media suppported files for ubantu |
| Ex on the beach torrent download 1080 | Acer aspire 3 wifi driver download |
| Audio sound effects software free download | Download torrent begin again |
| Download digital version of ultimate risk 1996 | Free download wwe 2k17 for ps4 |
Categories
This article was contributed by Will Webberley
Will is a computer scientist and is enthused by nearly all aspects of the technology domain. He is specifically interested in mobile and social computing and is currently a researcher in this area at Cardiff University.
Last updated 24 November 2020
Web applications often require the ability to allow users to upload files such as images, movies and archives. Amazon S3 is a popular and reliable storage option for these files.
This article demonstrates how to create a Python application that uploads files directly to S3 instead of via a web application, utilising S3’s Cross-Origin Resource Sharing (CORS) support. The article and companion repository consider Python 2.7, but should be mostly also compatible with Python 3.3 and above except where noted below.
Uploading directly to S3
A complete example of the code discussed in this article is available for direct use in this GitHub repository.
The main advantage of direct uploading is that the load on your application’s dynos would be considerably reduced. Using server-side processes for receiving files and transferring to S3 can needlessly tie up your dynos and will mean that they will not be able to respond to simultaneous web requests as efficiently.
If your application relies on some form of file processing between the client’s computer and S3 (such as parsing Exif information or applying watermarks to images), then you may need to employ the use of extra dynos and pass the upload through your webserver.
The application uses client-side JavaScript and Python for signing the requests. It will therefore be a suitable guide for developing applications for the Flask, Bottle and Django web frameworks. The upload is carried out asynchronously so that you can decide how to handle your application’s flow after the upload has completed (for example, a page redirect upon successful upload rather than a full page refresh).
An example simple account-editing scenario is used as a guide for completing the various steps required to accomplish the direct upload and to relate the application of this to a wider range of use-cases. More information on this scenario is provided later.
Overview
S3 is comprised of a set of buckets, each with a globally unique name, in which individual files (known as objects) and directories, can be stored.
For uploading files to S3, you will need an Access Key ID and a Secret Access Key, which act as a username and password. The access key account will need to have sufficient access privileges to the target bucket in order for the upload to be successful.
Please see the S3 Article for more information on this, creating buckets and finding your Access Key ID and Secret Access Key.
The method described in this article involves the use of client-side JavaScript and server-side Python. In general, the completed image-upload process follows these steps:
- A file is selected for upload by the user in their web browser;
- JavaScript is then responsible for making a request to your web application on Heroku, which produces a temporary signature with which to sign the upload request;
- The temporary signed request is returned to the browser in JSON format;
- JavaScript then uploads the file directly to Amazon S3 using the signed request supplied by your Python application.
This guide includes information on how to implement the client-side and server-side code to form the complete system. After following the guide, you should have a working barebones system, allowing your users to upload files to S3. However, it is usually worth adding extra functionality to help improve the security of the system and to tailor it for your own particular uses. Pointers for this are mentioned in the appropriate parts of the guide.
Prerequisites
- The Heroku CLI has been installed;
- A Heroku application has been created for the current project;
- An AWS S3 bucket has been created. For demonstration purposes we assume a bucket has been created that permits the creation of public objects. In a production environment you may want to use private objects that can be accessed via signed URLs.
During the first few hours after a bucket has been created S3 may return redirects in response to upload requests. If you notice this behaviour, then waiting a short while for your new bucket to completely settle should fix the problem.
Initial setup
Heroku setup
In order for your application to access the AWS credentials for signing upload requests, they will need to be added as configuration variables in Heroku:
If you are testing locally before deployment, remember to add the credentials to your local machine’s environment, too.
In addition to the AWS access credentials, set your target S3 bucket’s name (not the bucket’s ARN):
Using config vars is preferable over configuration files for security reasons. Try to avoid placing passwords and access keys directly in your application’s code or in configuration files.
S3 setup
You will now need to edit some of the permissions properties of the target S3 bucket so that the final request has sufficient privileges to write to the bucket. In a web-browser, sign in to the AWS console and select the S3 section. Select the appropriate bucket and click the tab. A few options are now provided on this page (including Block public access, Access Control List, Bucket Policy, and CORS configuration).
Firstly, ensure that “Block all public access” is turned off, and in particular turn off “Block public access to buckets and objects granted through new access control lists” and “Block public access to buckets and objects granted through any access control lists” for the purposes of this project. Setting up the bucket in this way allows us to read its contents without signed URLs, but this may not be suitable for services running in production.
Next, you will need to configure the bucket’s CORS (Cross-Origin Resource Sharing) settings, which will allow your application to access content in the S3 bucket. Each rule should specify a set of domains from which access to the bucket is granted and also the methods and headers permitted from those domains.
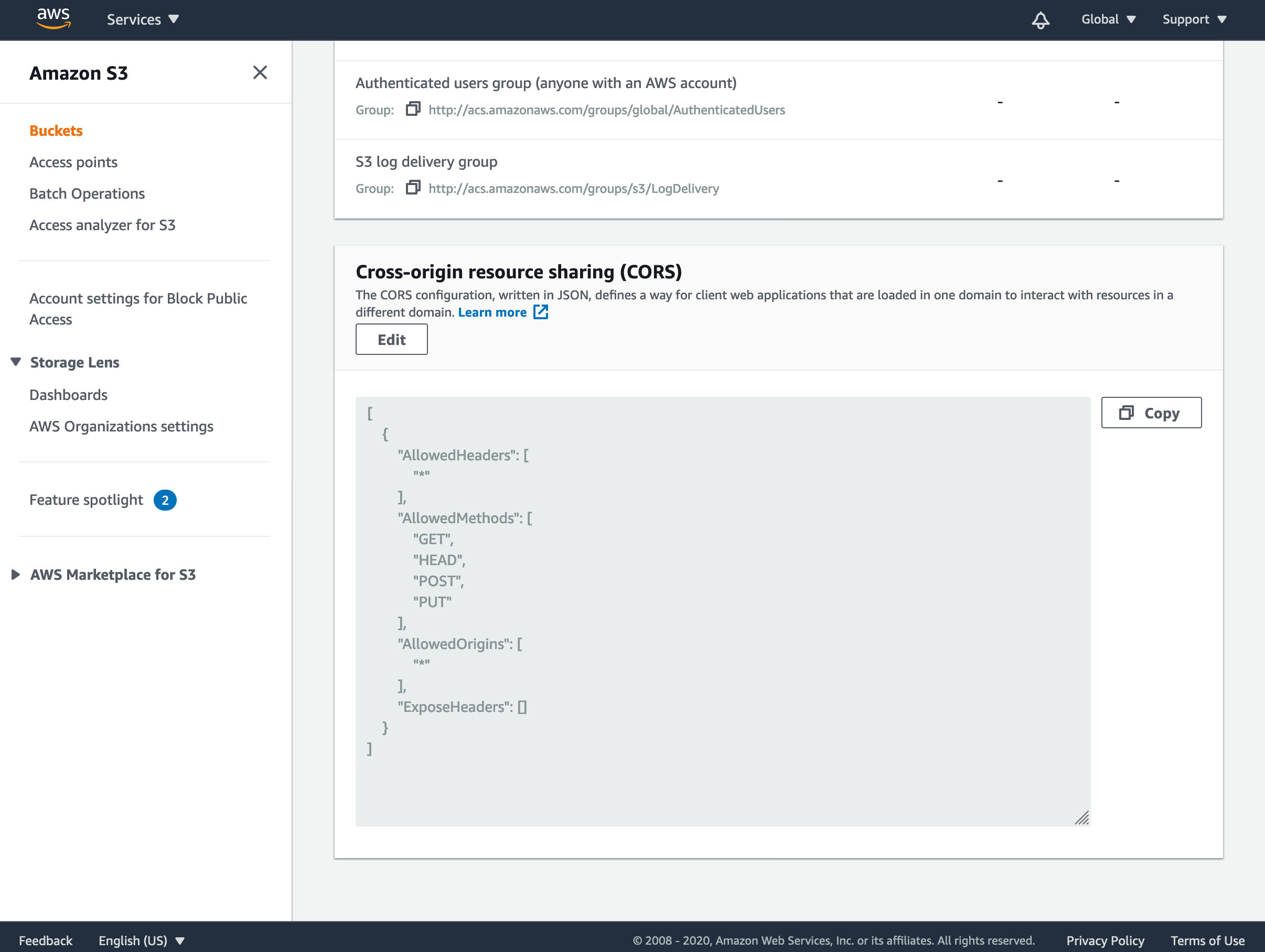
For this to work in your application, click and enter the following JSON:
Click and close the editor.
This tells S3 to allow any domain access to the bucket and that requests can contain any headers. For security, you can change the ‘AllowedOrigins’ array to only accept requests from your domain.
If you wish to use S3 credentials specifically for this application, then more keys can be generated in the AWS account pages. This provides further security, since you can designate a very specific set of requests that this set of keys are able to perform. If this is preferable to you, then you will need to also set up an IAM user in the Edit bucket policy option in your S3 bucket. There are various guides on AWS’s web pages detailing how this can be accomplished.
Direct uploading
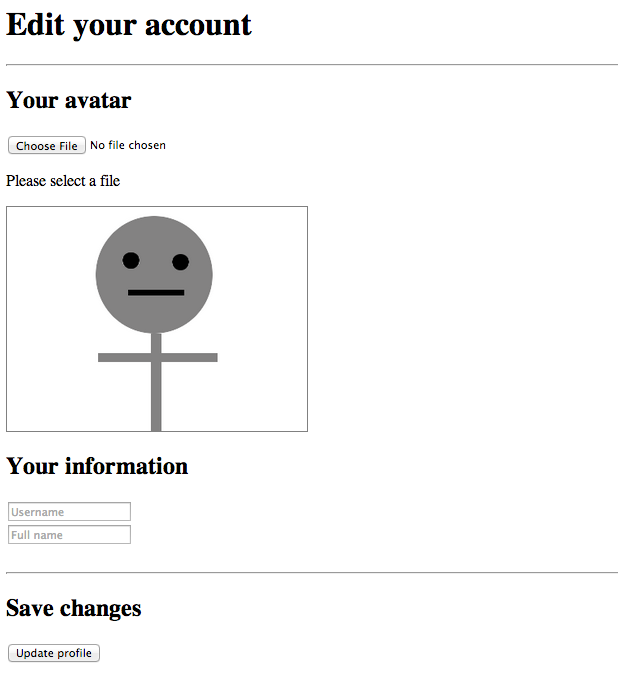
The processes and steps required to accomplish a direct upload to S3 will be demonstrated through the use of a simple profile-editing scenario for the purposes of this article. This example will involve the user being permitted to select an avatar image to upload and enter some basic information to be stored as part of their account.
In this scenario, the following procedure will take place:
- The user is presented with a web page, containing elements encouraging the user to choose an image to upload as their avatar and to enter a username and their own name.
- An element is responsible for maintaining a preview of the chosen image by the user. By default, and if no image is chosen for upload, a default avatar image is used instead (making the image-upload effectively optional to the user in this scenario).
- When a user selects an image to be uploaded, the upload to S3 is handled automatically and asynchronously with the process described earlier in this article. The image preview is then updated with the selected image once the upload is complete and successful.
- The user is then free to move on to filling in the rest of the information.
- The user then clicks the button, which posts the username, name and the URL of the uploaded image to the Python application to be checked and/or stored. If no image was uploaded by the user earlier the default avatar image URL is posted instead.
Setting up the client-side code
No third-party code is required to complete the implementation on the client-side.
The HTML and JavaScript can now be created to handle the file selection, obtain the request and signature from your Python application, and then finally make the upload request.
Firstly, create a file called in your application’s templates directory and populate the and other necessary HTML tags appropriately for your application. In the body of this HTML file, include a file input and an element that will contain status updates on the upload progress. In addition to this, create a form to allow the user to enter their username and full name and a hidden element to hold the URL of the chosen avatar image:
To see the completed HTML file, please see the appropriate code in the companion repository.
The element initially holds a default avatar image (which would become the user’s avatar if a new image is not chosen), and the input maintains the current URL of the user’s chosen avatar image. Both of these are updated by the JavaScript, discussed below, when the user selects a new avatar.
Thus when the user finally clicks the button, the URL of the avatar is submitted, along with the username and full name of the user, to your desired endpoint for server-side handling.
The client-side code is responsible for achieving two things:
- Retrieve a signed request from the app with which the image can be POSTed to S3
- Actually POST the image to S3 using the signed request
JavaScript’s objects can be created and used for making asynchronous HTTP requests.
To accomplish this, first create a block and write some code that listens for changes in the file input, once the document has loaded, and starts the upload process.
The code also determines the file object itself to be uploaded. If one has been selected properly, it proceeds to call a function to obtain a signed POST request for the file. Next, therefore, write a function that accepts the file object and retrieves an appropriate signed request for it from the app.
The above function passes the file’s name and mime type as parameters to the GET request since these are needed in the construction of the signed request, as will be covered later in this article. If the retrieval of the signed request was successful, the function continues by calling a function to upload the actual file:
This function accepts the file to be uploaded, the S3 request data, and the URL representing the eventual location of the avatar image. The latter two arguments will be returned as part of the response from the app. The function, if the request is successful, updates the preview element to the new avatar image and stores the URL in the hidden input so that it can be submitted for storage in the app.
Now, once the user has completed the rest of the form and clicked , the name, username, and avatar image can all be posted to the same endpoint.
If you find that the page isn’t working as you intend after implementing the system, then consider using to record any errors that are revealed by the function and use your browser’s error console to help diagnose the problem.
It is good practice to inform the user of any prolonged activity in any form of application (web- or device-based) and to display updates on changes. Therefore a loading indicator could be displayed between selecting a file and the upload being completed. Without this sort of information, users may suspect that the page has crashed, and could try to refresh the page or otherwise disrupt the upload process.
Setting up the server-side Python code
This section discusses the use of Python for generating a temporary signature with which the upload request can be signed. This temporary signature uses the AWS access key and secret access key as a basis for the signature, but users will not have direct access to this information. After the signature has expired, then upload requests with the same signature will not be successful.
As mentioned previously, this article covers the production of an application for the Flask framework, although the steps for other Python frameworks will be similar. Readers using Python 3 should consider the relevant information on Flask’s website before continuing.
To see the completed Python file, please see the appropriate code in the companion repository.
Start by creating your main application file, , and set up your skeleton application appropriately:
The currently-unused import statements will be necessary later on. boto3 is a Python library that will generate the pre-signed POST request. This, along with Flask, can be installed simply using .
Next, in the same file, you will need to create the views responsible for returning the correct information back to the user’s browser when requests are made to various URLs. First define view for requests to to return the page , which contains the form for the user to complete:
Please note that the views for the application will need to be placed between the and lines in .
Now create the view, in the same Python file, that is responsible for generating and returning the signature with which the client-side JavaScript can upload the image. This is the first request made by the client before attempting an upload to S3. This view responds with requests to :
If your bucket is in a region that requires a v4 signature, then you can modify your client configuration to declare this:
This code performs the following steps:
- The request is received to and the S3 bucket name is loaded from the environment.
- The name and mime type of the object to be uploaded are extracted from the parameters of the request (this stage may differ in other frameworks). The parameters are provided by the JavaScript discussed in the previous section.
- An S3 client is constructed using the library. At this stage, the and set earlier are automatically read from the environment.
- The pre-signed POST request data is then generated using the function. To this is passed the bucket name, the name of the file, some parameters to allow the uploaded file to be publicly readable, and an expiry time of the signed request (in seconds).
- Finally, the pre-signed request data and the location of the eventual file on S3 are returned to the client as JSON.
You may wish to assign another, customised name to the object instead of using the one that the file is already named with, which is useful for preventing accidental overwrites in the S3 bucket. This name could be related to the ID of the user’s account, for example. If not, you should provide some method for properly quoting the name in case there are spaces or other awkward characters present. In addition, this is the stage at which you could provide checks on the uploaded file in order to restrict access to certain file types. For example, a simple check could be implemented to allow only files to proceed beyond this point.
Finally, in , create the view responsible for receiving the account information after the user has uploaded an avatar, filled in the form, and clicked . Since this will be a request, this will also need to be defined as an ‘allowed access method’. This method will respond to requests to the URL :
In this example, an function has been called, but creation of this method is not covered in this article. In your application, you should provide some functionality, at this stage, to allow the app to store these account details in some form of database and correctly associate the information with the rest of the user’s account details.
In addition, the URL for the profile page has not been defined in this article (or companion code). Ideally, for example, after updating the account, the user would be redirected back to their own profile so that they can see the updated information.
Running the app
Everything should now be in place to perform the direct uploads to S3. To test the upload, save any changes and use to start the application:
You will need a Procfile for this to be successful. See Getting Started with Python on Heroku for information on the Heroku CLI and running your app locally. Also remember to correctly set your environment variables on your own machine before running the application locally.
Press to return to the prompt. If your application is returning errors (or other server-based issues), then start your server in debug mode and view the output in the Terminal emulator to help fix your problem. For example, in Flask:
Summary
This article covers uploading to Amazon S3 directly from the browser using Python to temporarily sign the upload request. Although the guide and companion code focuses on the Flask framework, the idea should easily carry over to other Python applications.

-
-